* 개인 공부용으로 작성하였습니다. 틀린 부분은 피드백 부탁드립니다.
Z. Fang, J. Wang, J. Geng and X. Kan, "Feature Selection for Malware Detection Based on Reinforcement Learning," in IEEE Access, vol. 7, pp. 176177-176187, 2019, doi: 10.1109/ACCESS.2019.2957429.
출처 :
https://ieeexplore.ieee.org/document/8920059
Feature Selection for Malware Detection Based on Reinforcement Learning
Machine learning based malware detection has been proved great success in the past few years. Most of the conventional methods are based on supervised learning, which relies on static features with labels. While selecting static features requires both huma
ieeexplore.ieee.org
1. 연구 주제 및 목표
- Malware Classification을 위한 Feature Selection을 자동으로 수행하는 DQFSA(Deep Q-learning based Feature Selection Architecture) 시스템 구현
- Feature Selection 프로세스를 Markov Decision Process로 모델링.
- Deep Q-learning를 MDP에 적용하여 Agent가 작동할 때 최고의 리워드를 도출하는 정책을 학습.
- 머신러닝 분류 모델의 정확도(Accuracy)를 Reward로 제공.
- 인간의 개입(Human Intervention) 없이 Malware Classification을 높은 성능으로 수행할 수 있는 최적의 Feature를 선택하는 것을 목표로 함
2. 배경 지식
Index Terms
- Malware : 컴퓨터 시스템에서 민감한 정보를 수집하거나 컴퓨터 시스템에 무단으로 접근하여 컴퓨터, 서버, 클라이언트, 네트워크 등에 악영향을 끼칠 수 있는 악성 소프트웨어.
- Feature Selection : 기계 학습에서 모델 성능을 높이기 위해 필요한 변수(feature, 속성 혹은 기능)를 선택하는 기술.
기존 Feature Selection의 문제점
- 수동으로 이루어지며, 전문가의 경험(Human Experience)에 의존적임.
- 추출된 Feature가 모든 샘플의 특성을 반영하지 못함.
- 광범위한 Feature 선택은 높은 탐지 성능을 낼 수 있지만 학습 시간이 오래 걸림.
3. 기존 연구 (Related Work)
1) Signature Feature Extraction
새 Malware file의 Header 혹은 Hash Code 같은 고유 번호를 이미 알려진 malware file의 고유번호를 저장한 데이터베이스에서 매핑을 통해 탐지.
2) Format Information Extraction
Malware와 정상 소프트웨어(Benign Software)의 정적 구조 특성이 다른 점을 Feature로 사용하는 방법.
3) N-Gram Features (Unstructured Feature Extraction)
바이너리 파일 전체를 길이 N의 substring으로 나누는 방법.
4) Multiple Abstract Feature Extraction
Single view features 보완을 위한 Multi-view features 제안. 탐지 성능 향상.
4.1. 연구 내용 | 주요 기여도 (Contributions)
- 인간의 개입(Human Intervention)을 줄이고 자동으로 Malware Classification을 위한 Feature Selection을 수행하는 시스템 구현.
- 기존 연구에 비해 더 적은 Feature를 사용하여 더 높은 성능 기준을 만족시킴.
- 이전에 강화학습을 이용한 Malware Classification 목적의 Feature Selection에 대한 연구는 없었음.
4.2 연구 내용 | 전체 구조(Framework Overview)

1) 데이터 수집, 전처리
- Malware 데이터 : VirusTotal Dataset로부터 수집 => 전처리 후 총 12146개 데이터 사용
- 정상 소프트웨어 데이터 : WIN10 Program Files Directory로부터 수집 => 전처리 후 총 9057개 데이터 사용
2) Feature 추출
- Format Features, N-grams Features : 두 Feature를 입력으로 Feature Vector를 만들고, 이 벡터가 강화학습기반 모델의 input으로 사용됨
3) 강화학습 기반 Training
- Reward : 분류 모델의 정확도. 분류 성능이 높은 피처에 높은 리워드를 제공
4.3. 강화학습 - (1) Environment
1) Format Features : 파일 내 헤더, 섹션 등의 정보. 총 204개 사용.

2) Bytes N-grams Features
Malware를 이진 바이너리 파일로 표현한 후, N에 따라 substring을 추출한 바이트 패턴을 시그니처로 사용.
- TF : 해당 바이트 패턴(n-gram)이 발생하는 빈도수
- IDF : 전체 샘플에서 특정 바이트 패턴(n-gram)을 포함하는 샘플 수의 비율

4.3. 강화학습 - (2) Action
1) Action Space
Terminal State에 도달할 때까지 Feature Selection 수행
2) Action Space Strategy
- State-Action Space를 제한하고, Agent가 특정 Action을 취하는 것을 제한함
- Terminal State까지 가지 않더라도 언제든지 종료 가능
- 이전에 선택한 Feature는 다시 선택할 수 없음
4.3. 강화학습 - (3) Reward
Reward : 각 분류 모델의 정확도
Agent에 올바른 Action이 무엇인지 알려주는 것이 아닌 긍정/부정적인 평가만 제공
4.3. 강화학습 - (4) 학습 과정
MDP for feature Selection

5.1. 연구결과 - 분류 모델 간 성능 비교
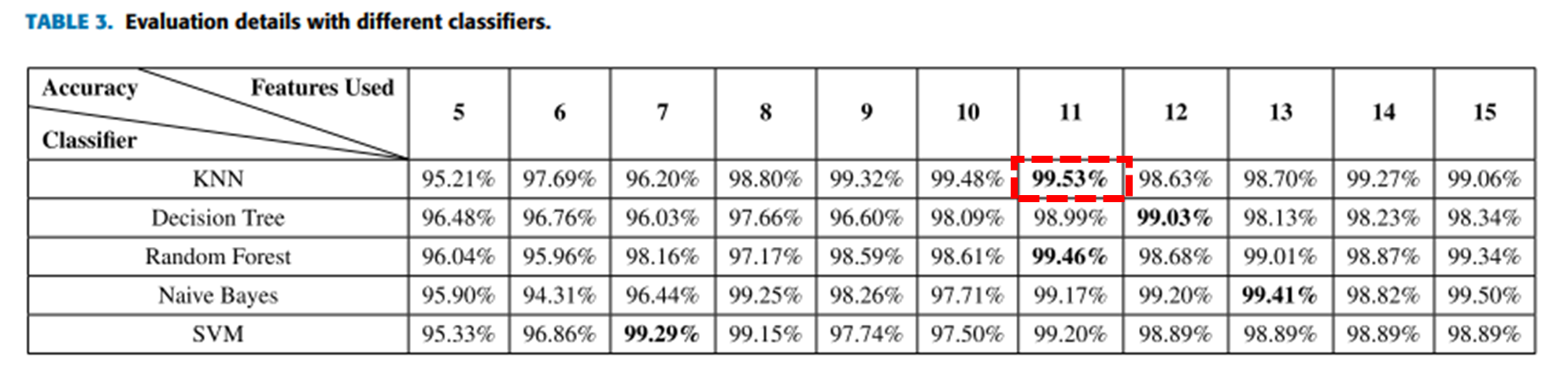
-
실험한 5가지 분류 모델에 대해 높은 성능 (96 ~ 99% Accuracy)을 보임
- 성능이 가장 높은 경우는 KNN 모델을 사용하고, 피처 11개 선택했을 때
5.2. 연구결과 - 기존 연구와 성능 비교

기존 연구에 비해
1) 실험한 모든 분류 모델에 대해 높은 성능 (특히 SVM)
2) 더 적은 Feature 선택
* 기존 연구 : 파일의 정적 구조 특성(Format Information Extraction)을 이용한 탐지 연구
5.3. 연구결과 - 결과
DQFSA 아키텍쳐
사람의 개입없이 샘플 기능 공간과 지속적으로 상호작용하는 AI 에이전트 제안.
'머신러닝' 카테고리의 다른 글
| [강화학습] Markov Decision Process (MDP) (0) | 2022.07.21 |
|---|---|
| [강화학습] 관련 용어 및 표기 (0) | 2022.07.21 |
| [군집화] #6. DBSCAN (0) | 2022.07.19 |
| [군집화] #5. GMM (0) | 2022.07.19 |
| [군집화] #4. 평균이동 (0) | 2022.07.19 |