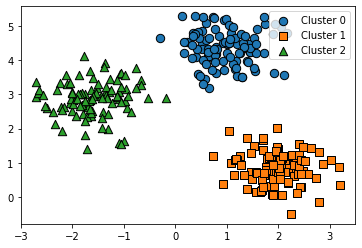
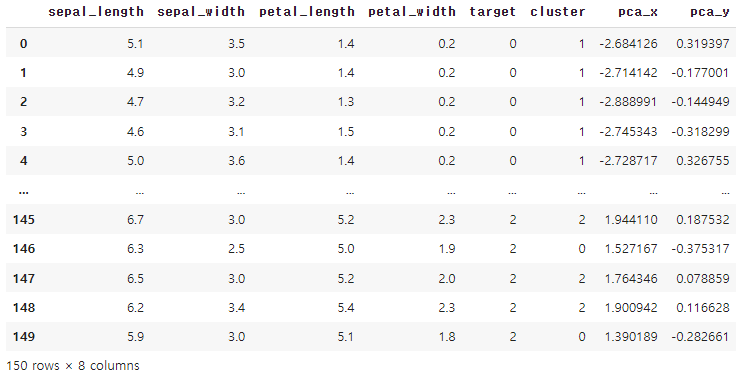
Planning : MDP를 알고 있을 때(model-based) 최적의(optimal) value, policy를 찾는 것. Dynamic Programming(DP) : 전체 큰 문제를 여러 개의 작은 문제(sub problem)로 분할해서 솔루션을 찾고 합쳐서 큰 문제를 해결하는 것. - MDP는 두 조건을 모두 충족함. 1) Optimal Substructure : sub problem으로 분할 가능해야하며, 각각에 대한 optimal한 솔루션이 있어야 함. => MDP는 bellman equation 통해 recursive하게 분해할 수 있음 2) 각각의 sub problem들이 같은 형태로 되어있어 하나의 sub problem에서 사용했던 ..