* "파이썬 머신러닝 완벽 가이드" 서적, 여러 개인 블로그들을 참고한 개인 공부용입니다
GMM
GMM은 데이터가 여러 개의 정규 분포를 가진 데이터 집합들이 섞여서 생성된 것이라는 가정하에 군집화를 수행한다.
GMM은 여러 개의 정규 분포 곡선을 추출하고, 개별 데이터가 그 중 어떤 정규 분포에 속하는지 결정한다.
이와 같은 방식은 GMM에서는 모수 추정이라고 하는데, 모수 추정은 대표적으로 2가지를 추정한다.
- 개별 정규 분포의 평균과 분산
- 각 데이터가 어떤 정규 분포에 해당되는지의 확률
모수 추정을 위해 GMM은 EM(Expectation and Maximization) 방법을 적용한다.
from sklearn.datasets import load_iris
iris = load_iris()
feature_names = ['sepal_length','sepal_width','petal_length','petal_width']
iris_df = pd.DataFrame(iris.data, columns = feature_names)
iris_df["target"] = iris.target
from sklearn.mixture import GaussianMixture
# n_components :군집 개수
gmm = GaussianMixture(n_components=3, random_state=0)
gmm.fit(iris.data)
gmm_cluster_labels = gmm.predict(iris.data)
# target, gmm_cluster 비교
iris_df["gmm_cluster"] = gmm_cluster_labels
iris_df.groupby(["target","gmm_cluster"]).size()target gmm_cluster
0 0 50
1 1 5
2 45
2 1 50
dtype: int64
- target이 1인 경우, 5개만 다르게 매핑되고 나머지는 모두 잘 매핑되었다.
GMM vs K-means
- 데이터 분포가 원형일 때 => K-means
- 데이터 분포가 타원일 때 => GMM
GMM 장점
K-Means보다 유연하게 다양한 데이터에 사용 가능
GMM 단점
알고리즘 수행 시간이 오래 걸림
[시각화 함수]
def visualize_cluster_plot(clusterobj, dataframe, label_name, iscenter=True):
# 군집별 중심 위치: K-Means, Mean Shift 등
if iscenter:
centers = clusterobj.cluster_centers_
# Cluster 값 종류
unique_labels = np.unique(dataframe[label_name].values)
markers=['o', 's', '^', 'x', '*']
isNoise=False
for label in unique_labels:
# 군집별 데이터 프레임
label_cluster = dataframe[dataframe[label_name]==label]
if label == -1:
cluster_legend = 'Noise'
isNoise=True
else:
cluster_legend = 'Cluster '+str(label)
# 각 군집 시각화
plt.scatter(x=label_cluster['ftr1'], y=label_cluster['ftr2'], s=70,
edgecolor='k', marker=markers[label], label=cluster_legend)
# 군집별 중심 위치 시각화
if iscenter:
center_x_y = centers[label]
plt.scatter(x=center_x_y[0], y=center_x_y[1], s=250, color='white',
alpha=0.9, edgecolor='k', marker=markers[label])
plt.scatter(x=center_x_y[0], y=center_x_y[1], s=70, color='k',\
edgecolor='k', marker='$%d$' % label)
if isNoise:
legend_loc='upper center'
else:
legend_loc='upper right'
plt.legend(loc=legend_loc)
plt.show()
[원형의 가상데이터 원본 시각화]
#데이터 원본 분포
from sklearn.datasets import make_blobs
# 가상데이터
X, y = make_blobs(n_samples=300, n_features=2, centers=3, cluster_std=0.5, random_state=0)
# 데이터 프레임
cluster_df = pd.DataFrame(X, columns=["ftr1","ftr2"])
cluster_df["target"] = y
# 가상데이터 시각화
visualize_cluster_plot(None, cluster_df, "target", iscenter=False)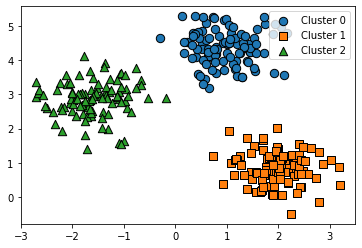
[원형의 가상데이터 K-means]
#원형 K-means
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
kmeans_label = kmeans.fit_predict(X)
# 군집 레이블 추가
cluster_df["kmeans_label"] = kmeans_label
# 군집분석 시각화
visualize_cluster_plot(kmeans, cluster_df, "kmeans_label", iscenter=True)
[타원의 가상데이터 원본]
#타원형 원본
transformation = [[0.60834549, -0.63667341], [-0.40887718, 0.85253229]]# 길게 늘어난 타원형의 데이터 셋을 생성하기 위해 변환함.
X_aniso = X @ transformation
# 데이터 프레임
cluster_df = pd.DataFrame(X_aniso, columns=["ftr1","ftr2"])
cluster_df["target"] = y
# 가상데이터 시각화
visualize_cluster_plot(None, cluster_df, "target", iscenter=False)
[타원의 가상데이터 K-means]
# 타원형 KMeans
kmeans = KMeans(n_clusters=3, random_state=0)
kmeans_label = kmeans.fit_predict(X_aniso)
# 군집 레이블 추가
cluster_df["kmeans_label"] = kmeans_label
# 군집분석 시각화
visualize_cluster_plot(kmeans, cluster_df, "kmeans_label", iscenter=True)
[타원의 가상데이터 GMM]
# 타원형 GMM
gmm = GaussianMixture(n_components=3, random_state=0)
gmm_label = gmm.fit_predict(X_aniso)
# 군집 레이블 추가
cluster_df["gmm_label"] = gmm_label
# GMM은 cluster_centers_ 속성이 없음
visualize_cluster_plot(gmm, cluster_df, 'gmm_label',iscenter=False)
* K-means와 시각화에 대해서는 아래 글을 참고해 주세요
2022.03.22 - [머신러닝] - [군집화] #1. K-means 알고리즘
[군집화] #1. K-means 알고리즘
* "파이썬 머신러닝 완벽 가이드" 서적, 여러 개인 블로그들을 참고한 개인 공부용입니다 군집화 비지도학습의 대표적인 기술로 x에대한 레이블이 지정 되어있지 않은 데이터를 그룹핑하는 분석
gabbung.tistory.com
2022.07.15 - [머신러닝] - [군집화] #2. 군집 시각화 (PCA, 군집 가상데이터 생성, K-means)
[군집화] #2. 군집 시각화 (PCA, 군집 가상데이터 생성, K-means)
* "파이썬 머신러닝 완벽 가이드" 서적, 여러 개인 블로그들을 참고한 개인 공부용입니다 군집 시각화 (iris) 2차원 평면상에서 iris 데이터의 속성 4개를 모두 표현하는 것이 적합하지 않아 PCA를 이
gabbung.tistory.com
'머신러닝' 카테고리의 다른 글
| [논문리뷰/강화학습/보안] Feature Selection for Malware Detection Based on Reinforcement Learning (0) | 2022.07.19 |
|---|---|
| [군집화] #6. DBSCAN (0) | 2022.07.19 |
| [군집화] #4. 평균이동 (0) | 2022.07.19 |
| [군집화] #3. 군집평가 (0) | 2022.07.15 |
| [군집화] #2. 군집 시각화 (PCA, 군집 가상데이터 생성, K-means) (1) | 2022.07.15 |