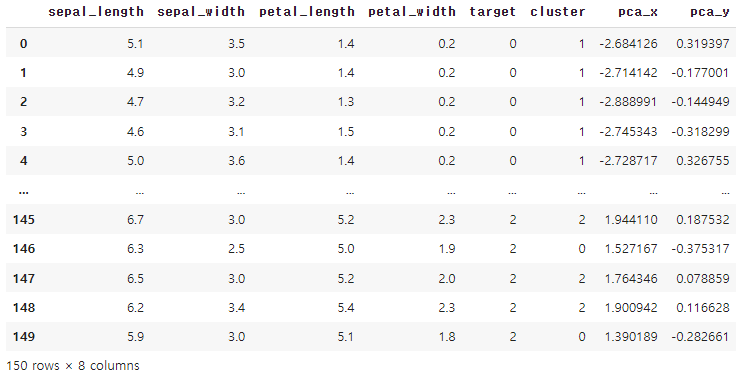
* "파이썬 머신러닝 완벽 가이드" 서적, 여러 개인 블로그들을 참고한 개인 공부용입니다 군집평가 비지도학습의 특성상 어떠한 지표라도 정확하게 성능을 평가하기 어렵다 실루엣 분석 다른 군집간은 비슷한 정도의 여유 거리가 있고, 동일 군집 데이터끼리는 가까운지 분석 실루엣 계수를 기반으로 하며 실루엣 계수는 개별 데이터가 가지는 군집화 지표이다. 실루엣 계수는 다음과 같이 표현할 수 있다. s(i) = (b(i)−a(i)) / max(a(i),b(i)) a(i): i번째 데이터에서 자신이 속한 군집내의 다른 데이터까지의 거리들의 평균 b(i): i번째 데이터에서 가장 가까운 타 군집내의 다른 데이터까지의 거리들의 평균 b(i)−a(i) : 두 군집 간 거리가 얼마나 떨어져 있는가 / max(a(i),b(i..