* "파이썬 머신러닝 완벽 가이드" 서적, 여러 개인 블로그들을 참고한 개인 공부용입니다
DBSCAN
대표적인 밀도 기반 군집화 알고리즘이다.
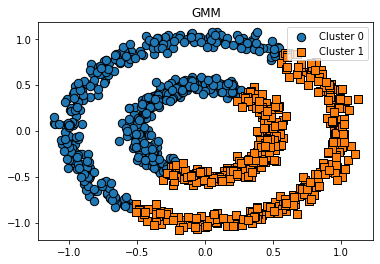
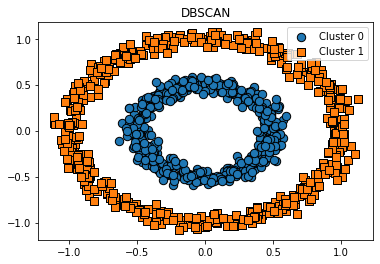
특정 공간 내에 데이터 밀도 차이를 기반 알고리즘으로 하고 있어 복잡한 기하학적 분포를 가진 데이터에도 군집화를 잘 수행한다. (K-means, 평균이동, GMM으로는 군집화 힘든 데이터)
DBSCAN 주요 파라미터
- 입실론 주변 영역(epsilon): 개별 데이터를 중심으로 입실론 반경을 가지는 원형의 영역
- 최소 데이터 개수(min points): 개별 데이터의 입실론 주변 영역에 포함되는 타 데이터의 갯수
DBSCAN 데이터 포인트
- 핵심 포인트(core point): 주변 영역 내에 최소 데이터 갯수 이상의 타 데이터를 가지고 있는 경우
- 이웃 포인트(neighbor point): 주변 영역 내에 위치한 타 데이터를 명칭
- 경계 포인트(border point): 핵심 포인트는 아니지만 핵심 포인트를 이웃 포인트로 가지는 데이터
- 잡음 포인트(noise point): 핵심 포인트가 아니면서 동시에 경계 포인트도 아닌 데이터
만약 핵심 포인트끼리 서로가 이웃 포인트라면 서로를 연결하면서 군집화를 구성한다.
경계 포인트의 경우 핵심 포인트의 이웃 포인트로서 군집의 외곽을 형성한다.
즉, 입실론 주변 영역의 최소 데이터 갯수를 포함하는 밀도 기준을 충족시키는 데이터인 핵심 포인트를 연결하면서 군집화를 한다.
from pandas.core.resample import TimedeltaIndexResamplerGroupby
# GMM에서 사용한 시각화 함수
def visualize_cluster_plot(clusterobj, dataframe, label_name, iscenter=True, title=None):
# 군집별 중심 위치: K-Means, Mean Shift 등
if iscenter:
centers = clusterobj.cluster_centers_
# Cluster 값 종류
unique_labels = np.unique(dataframe[label_name].values)
markers=['o', 's', '^', 'x', '*']
isNoise=False
for label in unique_labels:
# 군집별 데이터 프레임
label_cluster = dataframe[dataframe[label_name]==label]
if label == -1:
cluster_legend = 'Noise'
isNoise=True
else:
cluster_legend = 'Cluster '+str(label)
# 각 군집 시각화
plt.scatter(x=label_cluster['ftr1'], y=label_cluster['ftr2'], s=70,
edgecolor='k', marker=markers[label], label=cluster_legend)
# 군집별 중심 위치 시각화
if iscenter:
center_x_y = centers[label]
plt.scatter(x=center_x_y[0], y=center_x_y[1], s=250, color='white',
alpha=0.9, edgecolor='k', marker=markers[label])
plt.scatter(x=center_x_y[0], y=center_x_y[1], s=70, color='k',\
edgecolor='k', marker='$%d$' % label)
if isNoise:
legend_loc='upper center'
else:
legend_loc='upper right'
plt.legend(loc=legend_loc)
if title !=None:
plt.title(title)
plt.show()from sklearn.datasets import load_iris
iris = load_iris()
feature_names = ['sepal_length','sepal_width','petal_length','petal_width']
iris_df = pd.DataFrame(iris.data, columns = feature_names)
iris_df["target"] = iris.targetfrom sklearn.cluster import DBSCAN
#eps:입실론 주변 영역, min_samples : 최소 데이터 개수
dbscan = DBSCAN(eps = 0.6, min_samples = 8, metric = "euclidean")
dbscan_labels = dbscan.fit_predict(iris.data)
# cluster label 추가
iris_df["dbscan_cluster"] = dbscan_labels
iris_df.groupby(["target", "dbscan_cluster"]).size()target dbscan_cluster
0 -1 1
0 49
1 -1 4
1 46
2 -1 8
1 42
dtype: int64
- 결과를 보면 -1,0,1 값이 있는데 -1은 노이즈에 속하는 군집을 의미한다.
- 0, 1만 군집.
from sklearn.decomposition import PCA
# pca로 차원 축소. 피처 2개만 사용
pca = PCA(n_components=2, random_state=0)
pca_transformed = pca.fit_transform(iris.data)
# 데이터 프레임에 주성분 추가
iris_df["ftr1"] = pca_transformed[:,0]
iris_df["ftr2"] = pca_transformed[:,1]
visualize_cluster_plot(dbscan, iris_df, "dbscan_cluster", iscenter=False)
- PCA로 2차원으로 차원 축소 후, 시각화.
- 일반적으로 eps의 값을 크게 하면 반경이 커져 포함하는 데이터가 많아지므로 노이즈 개수가 감소.
- min_samples를 크게 하면 주어진 반경 내에서 더 많은 데이터를 포함해야므로 노이즈 개수가 증가.
# eps와 min_samples를 조정하면서 노이즈 갯수를 확인
# eps 0.6 -> 0.8
dbscan = DBSCAN(eps=0.8, min_samples=8, metric='euclidean')
dbscan_labels = dbscan.fit_predict(iris.data)
iris_df['dbscan_cluster'] = dbscan_labels
iris_df['target'] = iris.target
iris_result = iris_df.groupby(["target", "dbscan_cluster"]).size()
print(iris_result)
visualize_cluster_plot(dbscan, iris_df, 'dbscan_cluster', iscenter=False)target dbscan_cluster
0 0 50
1 1 50
2 -1 3
1 47
dtype: int64
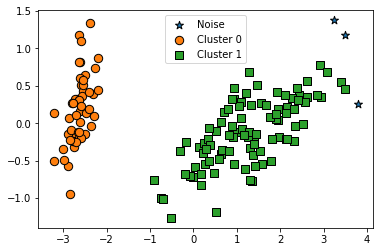
- eps 0.6 -> 0.8 변경 후 노이즈 감소
# min_samples: 8 -> 16
dbscan = DBSCAN(eps=0.6, min_samples=16, metric='euclidean')
dbscan_labels = dbscan.fit_predict(iris.data)
iris_df['dbscan_cluster'] = dbscan_labels
iris_df['target'] = iris.target
iris_result = iris_df.groupby(["target", "dbscan_cluster"]).size()
print(iris_result)
visualize_cluster_plot(dbscan, iris_df, 'dbscan_cluster', iscenter=False)target dbscan_cluster
0 -1 2
0 48
1 -1 6
1 44
2 -1 14
1 36
dtype: int64
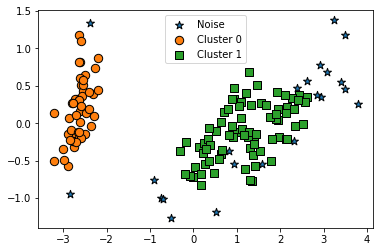
- min_samples 8->16으로 증가, 노이즈도 증가
# 가상데이터 시각화
from sklearn.datasets import make_circles
#make_circles: 중심 기반 군집화로 해결하기 어려운 데이터를 생성하며 2개의 피처만을 가진다
#noise: 노이즈 데이터의 비율.
#factor: 외부 원과 내부 원의 scale 비율
X, y = make_circles(n_samples=1000, shuffle=True, noise=0.05, random_state=0, factor=0.5)
cluster_df = pd.DataFrame(data=X, columns=['ftr1', 'ftr2'])
cluster_df['target'] = y
visualize_cluster_plot(None, cluster_df, 'target', iscenter=False)
####K-means
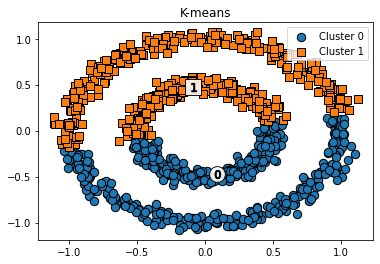
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2, max_iter=1000, random_state=0)
kmeans_labels = kmeans.fit_predict(X)
cluster_df["kmeans_cluster"] = kmeans_labels
visualize_cluster_plot(kmeans, cluster_df, 'kmeans_cluster', iscenter=True, title='K-means')
####GMM
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=2, random_state=0)
gmm_labels = gmm.fit_predict(X)
cluster_df["gmm_cluster"] = gmm_labels
visualize_cluster_plot(gmm, cluster_df, 'gmm_cluster', iscenter=False, title='GMM')
####DBSCAN
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.2, min_samples=10, metric="euclidean")
dbscan_labels = dbscan.fit_predict(X)
cluster_df["dbscan_cluster"] = dbscan_labels
visualize_cluster_plot(dbscan, cluster_df, 'dbscan_cluster', iscenter=False, title='DBSCAN')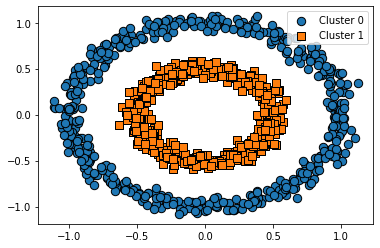
'머신러닝' 카테고리의 다른 글
| [강화학습] 관련 용어 및 표기 (0) | 2022.07.21 |
|---|---|
| [논문리뷰/강화학습/보안] Feature Selection for Malware Detection Based on Reinforcement Learning (0) | 2022.07.19 |
| [군집화] #5. GMM (0) | 2022.07.19 |
| [군집화] #4. 평균이동 (0) | 2022.07.19 |
| [군집화] #3. 군집평가 (0) | 2022.07.15 |