* "파이썬 머신러닝 완벽 가이드" 서적, 여러 개인 블로그들을 참고한 개인 공부용입니다
군집화
- 비지도학습의 대표적인 기술로 x에대한 레이블이 지정 되어있지 않은 데이터를 그룹핑하는 분석 알고리즘
- 데이터들의 특성을 고려해 비슷한 특성을 가진 데이터 집단(클러스터)을 정의하고 데이터 집단의 대표할 수 있는 중심점을 찾는 것
- 이상탐지에 사용됨
K-means

k-means 클러스터링은 데이터를 k개의 클러스터(cluster, 무리)로 분류
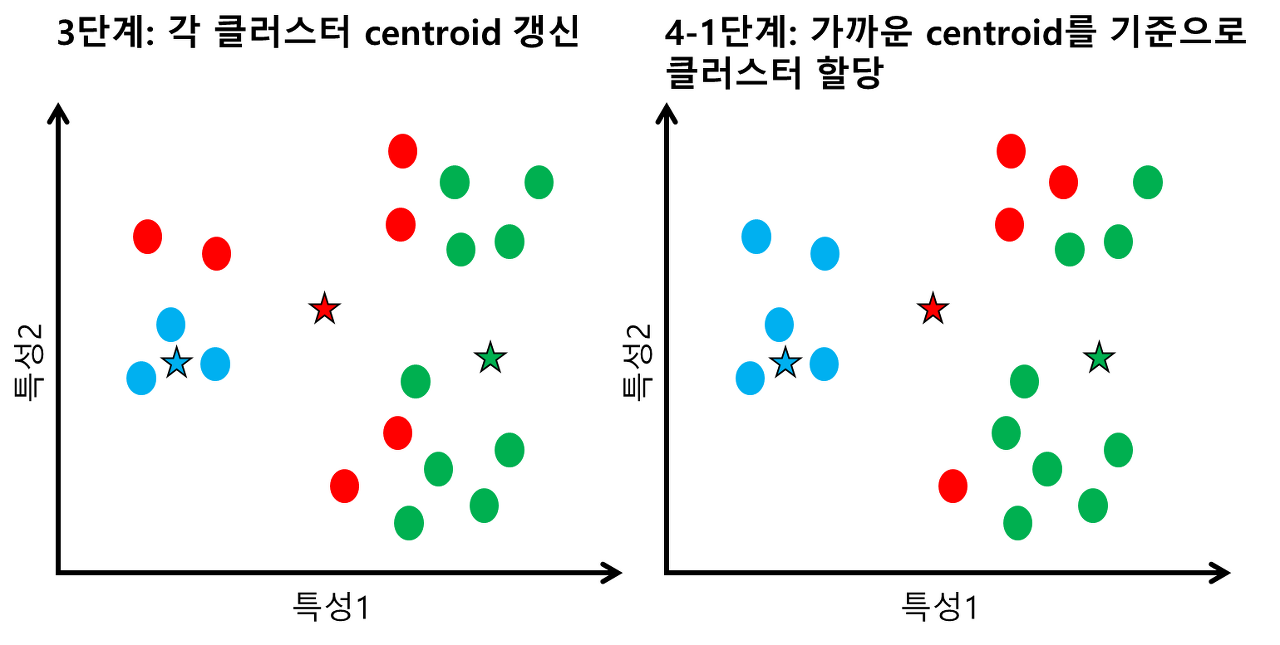
1) 사용자로부터 입력받은 k의 값에 따라, 임의로 클러스터 중심(centroid) k개를 설정해준다.
2) k개의 클러스터 중심으로부터 모든 데이터가 얼마나 떨어져 있는지 계산한 후에, 가장 가까운 클러스터 중심을 각 데이터의 클러스터로 정해준다.
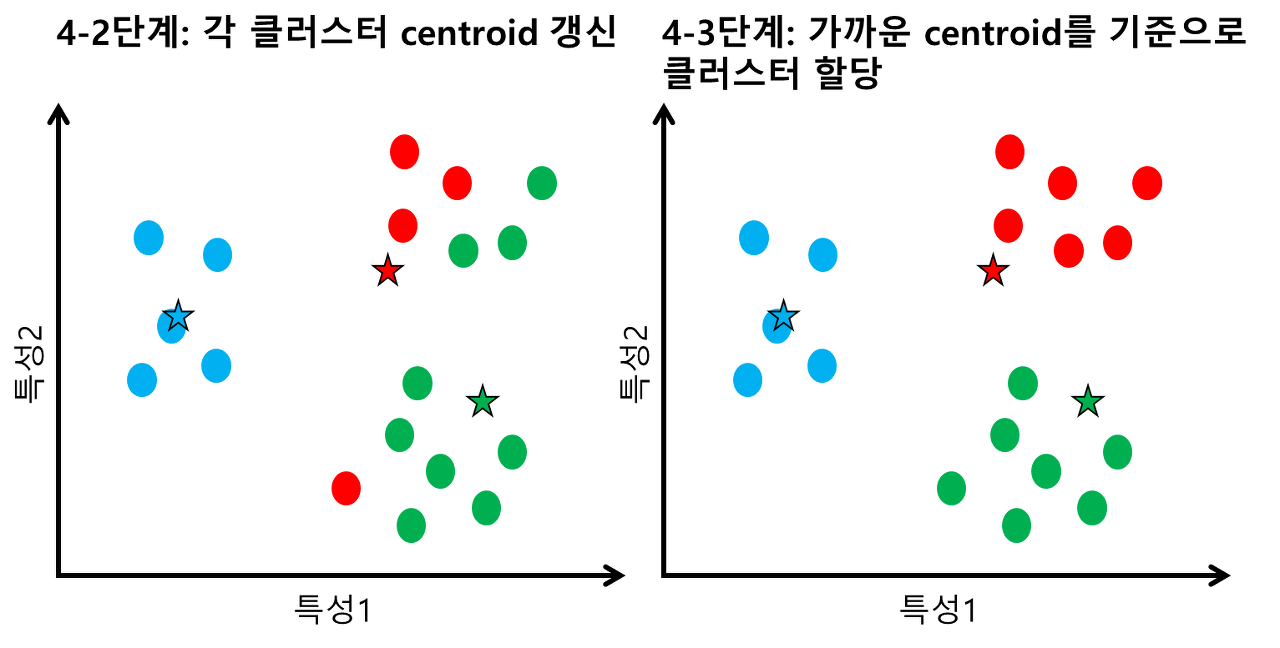
3) 각 클러스터에 속하는 데이터들의 평균을 계산함으로 클러스터 중심을 옮겨준다.
4) 보정된 클러스터 중심을 기준으로 2, 3단계를 반복한다.
5) 더이상 클러스터 중심이 이동하지 않으면 알고리즘을 종료한다.


- 장점
- 일반적으로 많이 사용
- 알고리즘이 쉽고 간결함
- 단점
- K값 선택이 어려움
- 반복 수행 시 수행 시간
- 거리 기반 알고리즘으로 속성의 개수가 많을 경우 군집화 정확도가 떨어짐(PCA로 차원 감소를 적용하기도 함)
- 거리의 평균값을 구하는 알고리즘이기 때문에 이상치에 취약함
예제 코드
from sklearn.preprocessing import scale
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
%matplotlib inline
iris = load_iris()
irisdf = pd.DataFrame(data = iris.data,
columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'])
#n_clusters : k값, init : 초기 중심 설정 방식. 일반적으로 'k-means++'이 디폴트 , max_iter: 최대 반복 횟수. 이 횟수 이전에 모든 데이터의 중심점 이동이 없으면 종료.
kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=300, random_state=0)
kmeans.fit(irisdf)
#각 데이터가 0,1,2라는 세 가지 군집으로 분류된 것을 확인.
print(kmeans.labels_)[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 2 2 2 2 0 2 2 2 2 2 2 0 0 2 2 2 2 0 2 0 2 0 2 2 0 0 2 2 2 2 2 0 2 2 2 2 0 2 2 2 0 2 2 2 0 2 2 0]
'머신러닝' 카테고리의 다른 글
| [군집화] #6. DBSCAN (0) | 2022.07.19 |
|---|---|
| [군집화] #5. GMM (0) | 2022.07.19 |
| [군집화] #4. 평균이동 (0) | 2022.07.19 |
| [군집화] #3. 군집평가 (0) | 2022.07.15 |
| [군집화] #2. 군집 시각화 (PCA, 군집 가상데이터 생성, K-means) (1) | 2022.07.15 |